FHIRとopenEHRの違いについて¶
(この記事はThomas Beale氏によるブログ記事FHIR compared to openEHRを翻訳したものです)

openEHRについて多くの個人や団体からこれまでの標準とどう違うのかという質問をうけてきました。今日ではHL7 FHIRとopenEHRがどう違うのか、どんな関係があるのかというような質問も増えてきました。
この問題について時折考え直してみるのは楽しいことです。特にeHealth標準の歴史について知りすぎていない一部の質問者の立場で考えてみるのは特に楽しいものです。この質問を理解するためには、いくつかの基本的な医療情報の概念に注目する必要があります。以下に私の回答を書いておきます。できるだけ客観的に回答しようとしましたが、私はいうまでもなくopenEHRについてFHIRよりも詳細までよく知っています。
相互運用性についての要求はどのように解決されますか?¶
従来から、システム内部はコントロールできないので、システム間で流れるデータ、たとえばメッセージを標準化の対象とする必要があると考えられてきました。それがHL7やEDIFACTなどの基本となる考え方です。この考え方は明確に定義された特定のデータすなわち、検査結果や処方箋では非常にうまく機能しています。まさに私がこれを書いている間にも、数百万のHL7 v2.3やv2.5のメッセージがいまだに多くのシステムから流れています。
しかし、私は以下のように(これはほとんどのopenEHR、13606やHL7 CIMIコミュニティも同意すると私が信じていることです)主張します。
- 過去20年間の経験では、分散したeHealth環境を実現するためには、メッセージに格納される特定のデータセットよりはるかに広い範囲にわたって共有する必要がありました。そして実際にそのセマンティクスは特定のベンダーによる製品の内部データ構造(たとえば画面の入力フォーム)や特定のメッセージフォーマットでさえ維持できないくらい複雑なものです。それらが意味するものはそれぞれの新しいフォーマット(UI表示、モバイルデータの取り込み、さまざまな文書フォーマットなど)や、技術(多様なデータベースやJavaScriptなど)で再現されなければなりません。
- データベーステーブルを画面に表示させることが多くのソリューションであった20年前とは違って、今日ではシステムを構築する人は内部データで必要となるセマンティクスについて熟知しています。
- そのドメインでのセマンティクスを理解する人々は、ITの技術者ではなく、そのドメインの専門家であり、深い専門知識を持つ医療情報の専門家です(最近の記事でこのことについて書きました )。
私の見解では、セマンティクスレベルでの相互運用性に関する仕様を策定するため唯一のスケーラブルな方法は、そのベンダーの製品や特定の通信フォーマットの外部で制作することです。これは、独自のフォーマットやツール、コミュニティにある既存のモデルを使った、 単一のソースによるモデルベースのアプローチを意味します。「モデル」の例としては、例えばICDx、SNOMED、ICFなどのターミノロジーです。 openEHRのアーキタイプやテンプレート、そしてHL7 CIMIのような他のグループによる機械処理可能なガイドラインや、医薬品集などもそうです。これらの多様なモデル((openEHRののものを含む)には2つの重要な特性があります。
- そのドメインでのセマンティクスを理解する専門家によって直接作成されます。
- メッセージフォーマットを含む、任意の合理的なフォーマットに機械的に変換することができます。

セマンティックスケーラビリティについてのこの記事には、ソースが単一であることや草の根的なアプローチの必要性について、図示して説明しています。
「システム理論」対「メッセージ理論」¶
上記の方法は相互運用性についての「システム」理論とされるものでしょう。セマンティクスはそのドメインで形式化され、システムやツールなどで使われる具体的な形(たとえばXSD、JSONベースの画面フォームなど)に機械的に変換され、メッセージやその他の保存形式としても利用されます。
相互運用性のメッセージ理論では、メッセージの (一般的な形式や通信プロトコルではなく)内容を標準化して、システムの適合要件とするか、または少なくともそのメッセージを通信チャネルの一部とします。この方法ではシステムからデータを取り出す一部の利用者から見るとよく機能する可能性がありますが、システム独自、あるいはモデルベースのセマンティクスを出力しようとするシステムにとっては、何らかの障害となりえます。標準化されたメッセージチャネル上で通信しようと準備するには、メッセージを作るために必要とされる構造と彼らのシステム内のデータを変換するためにプログラムを書かなければなりません。システム内のデータとメッセージは異なっていてもよく、それらの間でのマッピングは自明ではないこともありますが、どのようなマッピングでも、パフォーマンスや正確性、患者の安全性へのリスクがあります。メッセージとしてはデータセットが小さくシンプルなものであれば、問題はあまりないでしょうが、「何でも通信」することを可能にするためには非常に大きな問題を抱えることになります。
それでも、データをシリアライズして、それを特定の場所に届けなければいけないことがあります。システム理論では、モデルを最初に定義します。openEHRでは、ターミノロジーとの結合を含み、モデルから機械的に生成されてメッセージの定義ともなるテンプレートのことです。これはRPCgenのころから実際に行われていたことで現在でもたいした作業ではありません。したがって、 モデルベースのエコシステムでは特定のメッセージは必要なく、一般的なメッセージ技術があればよいのです 。この方法では、たった一つの形式だけが有効であるということではないと言うところに注目してください。データの受け渡しはXMLであっても、JSON,バイナリなど、あるいはPDFやOpenDocなどのような文書フォーマットでもよいのです。
したがって、 相互運用性のこれら二つの理論では、それぞれ二つの異なる場所にモデルがあります。openEHRが採用する「システム理論」では、モデルは製品や実際の通信フォーマットとは別の場所に置かれています。「メッセージ理論」では、特定の通信フォーマットの中にモデルが組み込まれています。
システム理論のやり方は技術的にはやや困難ですが、将来性もあり、よりスケーラブルです。メッセージ理論でやろうとすると、より手軽に成果を得ることができますが、フォーマットの変更が必要となったり、扱う内容が非常に大きくなった場合に問題に直面することになります。
メッセージ理論の限界については最近のこの記事にも書いています。
理想的な世界 - ユニバーサルモデル¶
eHealthの世界で最も理想的な方法は普遍的な臨床モデル(前に述べているとおり、「モデル」にはターミノロジーや、そのサブセット、アーキタイプ、テンプレート、ガイドラインなどを含みます)を開発することでしょう。そして、それらのモデルをシステムコンポーネントやデータベース、メッセージなどの資産として利用できるように構築するツールを開発することです。この理想的な方法についてはStan Huff先生により、2011年にCIMIが始まったときに明確に示されています。これは、私たちが90年代後半から考えてきたことであり、Stan Huff先生がIntermountain Healthcareで考えてきたことでもあります。そして、私達はずっと同じように探求していくことでしょう。(CIMIはいまはHL7技術委員会となっていますが、私はまだ同じような目的を持っていると考えています)。
言い換えてみると、「メッセージを送受信する」方法は、「モデルを構築」して、そして特定の状況に合わせたいずれかのメッセージあるいはそのほかのシリアライズ形式を生成することと同じこととなるでしょう。
しかしながら、国際標準における政治的力学やニーズの違い、それにともなう時系列やそのほかの多様な圧力によってこのモデル中心の手法は妨げられてきました。技術的に可能であり、現実に実装されていて世界的に使われているにもかかわらずです。
この種の作業にとって理想的な方法として、旧態依然とした標準化団体がやっているような「委員会により設計」されるものではなく、オープンソーススタイルでより開かれたプロジェクト形式(あるいは多くのプロジェクトによる共同作業)で開発を進めていく方法を私は提案したいと思います。そして、これがopenEHRで採用している方法です。
現実¶
私たちが実際に住んでいるこの世界では、物事はより複雑です。まず、人々はさまざまな課題を解決しようとしています。一つの課題は、これは統計的に間違いなくもっともよくある問題ですが、(一般的には契約であったり知的財産権といった理由で)使い続けなければいけないが、中身がよくわからないシステムがあって、その限定的な商用インターフェースかRDBMSのテーブルから直接データを取り出すような課題です。もう一つの課題は、たとえば情報やその処理、業務規則や臨床支援システムなどのヘルスケアにおける新しい理解を組み込んだ新しい世代のシステムやコンポーネントを構築することです。これらの試みはそれぞれ別個の方法に対応しています。
eHealthの標準の世界では、HL7は15年間HL7 v3の開発を続けてきましたが(新しい技術をうまく取り込むことができずに複雑になりすぎましたが、HL7 v2は非常によく機能していました)、2012年よりFHIRの開発を始めました。
私たちはopenEHRで、上記の「システム」理論で開発し続けててきました。関連するEN 13606コミュニティや、より最近ではCIMIコミュニティは、同様の基盤で開発してきましたし、いうまでもないですが、IHTSDOや薬剤DBを提供する会社やさまざまなガイドラインを発効している会社は同じような基盤をもって開発してきました(つまり、これらの組織が提供する製品の内容は特定のベンダーの製品や通信フォーマットに依存していません)。
FHIRと比べてopenEHRはどう違うのですか?¶
FHIRの主目的は、特定のシステムを仮定しない条件でシステム間(B2B)とシステムとアプリケーション(B2C)間の通信を解決することです。FHIRにおけるB2Bの部分は基本的に21世紀的なメッセージの方法です。 B2Cの部分はプログラミングに適したAPIを構築することが含まれ、要望の多くに対応しています。つまり、FHIRは現代的なeHealthアプリケーションを簡単に構築できるようにします。課題としては、APIを構築するためにはシステムが前提としているビジネスロジックや格納されるコンテンツが何かと言うことについて仮定するところから始めなければならないというところです。
openEHRの最初の目的は長期にわたってバージョン管理された患者についての記録を分散して機械可読な状態でデータを保存するという問題を解決することにあります。そして、それは将来性がありセマンティクスを有効に活用することができるプラットフォームアーキテクチャを開発することです。我々は、形式的セマンティクスに基づいたフレームワークで当然に得られる技術的成果として相互運用性について考えています。もちろん、openEHR自体では、単にこのようなプラットフォームの部分的な要素を提案しているだけで、ターミノロジーや、オントロジー、薬品データベース、サービス・インターフェースなどとあわせて使われるべきものであります。
技術的表現¶
FHIRは「リソース」のライブラリ(web-dataで用いられるmicro format) を定義しています。そして、技術的方法として「プロファイリング」と「拡張(extension)」(これらの用語はFHIRのWebサイトですべて定義されています)をローカライゼーションのために用意しています。言い換えれば、FHIRには開発中である水準に達した「臨床モデリング」がありますが、それはFHIR XMLマスター形式の内部で定義されたものです。リソースは、RESTのAPIを介してインスタンス化され、アクセスされるように設計されています。
openEHRには、標準的な参照モデルがあり、アーキタイプやテンプレートターミノロジーのサブセットを含むさまざまな層にわたるモデルが上位にあります。openEHRの参照モデルは、全世界で通用する標準であり、内容にかかわらず全てのopenEHRデータを表現することができます。openEHRと他のADLベースのコミュニティでは、 モデルはメッセージやWebマイクロフォーマットとは切り離されており その代わりに、必要に応じていずれかのフォームに機械的に変換されます。このためより多くのツールをつかいます。たとえば、基本的なXML、JSON、 GoogleのProtocolBuffers形式など何でもよいのですがそれらを生成するツール群です。しかし、実際にはこれらのフォーマットについての具体的な好みは変化しつつあります。FHIRが開発されているこの5年間でXMLからJSONが主流となり、優先されるようになってきました。
openEHRのアーキタイプはアーキタイプ定義言語(ADL)/アーキタイプオブジェクトモデル(AOM、ISO規格)で表現されます 。ADLはまた、HL7 CIMIモデルを表現するものでもあります。ADLとAOMは、一般的なモデルを特定の形式やローカライズした形式に適応させることができるように、合成や特殊化、再定義することをサポートしています。
構築されたモデルのスタイルにも違いがあります。openEHRおよびその関連技術では、モデルは臨床医学分野の専門家のコミュニティでその要求に基づいて、要件、つまり「私たちが本当に望むもの」に基づいて設計されます。FHIRでは、レガシーシステムにあるデータのスーパーセットをモデルとして各FHIRリソースを生成して、開発者のニーズに直接応えていくことを基本的な戦略としています。これは、異なる結果につながる - FHIRのモデルは、開発者が直接利用することができるものではありますが、たとえばUIフォームの生成など異なる技術体系の元では簡単に再利用できません。openEHRではツールを使ってXSDやJSON、Xforms、そして開発者が必要とする任意のフォーマットを生成します。
さらにopenEHRでは、EHRを構築するための基盤となる参照モデルを利用した張性の高いEHRのための理論的基礎があります。私はFHIRに同等のものがあるとは認識していません。そのため、FHIRをeHealthのインフラストラクチャとした場合の臨床プロセスにおける相互運用性で重要な問題となるのではないかと私は考えています。
最近の記事ではHL7とFHIRユーザーのためのopenEHRの技術的な基礎についてFHIRについて興味がある人向けにopenEHRについて詳しく書いています。
プラットフォームカバレッジ¶
技術的なコンピューティングプラットフォームが情報モデル、セマンティクスモデル、APIおよびクエリで構成されているという私達の一般的な考えに対して同意していただけるなら、さらにいくつかの比較を行うことができます。
openEHRは、患者情報(参照モデルで数多くの構造を定義しています)を広範囲にカバーしていて、セマンティクスモデルの分野でも重要な部分(一般的な診療の25%程度だと考えています)をカバーしています。アプリケーションAPIについてはまだ標準とはなっていないけれども良質なツールが作られていて、限定的にカバー(例)しています。APIについては2017年現在、取り組んでいる分野の一つで、新しいプロセスに関する仕様(現在、新規タスクプランニング仕様が公開されコメントを受け付けています)とともに作業を進めています。
FHIRがAPIでカバーしている範囲は、より広いものです。それはFHIRが得意とするところでもあり、実際にFHIRプロジェクトが複雑なデータをやりとりする方法については画期的なエンジニアリングを行ったと主張できるものです。
医療分野でのセマンティクスおよび情報モデルをどうカバーしていくかを決定するのはAPIを決定するよりも困難なものです。そして、それはFHIRリソースをどのようなものと考えるかにもよります。openEHRのアーキタイプのようなものなのか、それとも参照モデルのようなものなのか、はたまたその中間のようなものなのか。私は、FHIRリソースはopenEHRのtemplateライブラリのようなものだと見ています。再利用ができて、拡張のため特殊化することができるような仕様があります。それに加えて、IDやデータ型、一般的な構造や人名や住所などを表現できる基本的な型についての一般的なリソース群を備えています。FHIRとopenEHRの違いの1つは、FHIRリソースの構造がより複雑であることです。たとえば、FHIRのRisk Assesmentリソースですが、それ自体が独自のデータ構造を定義しています。openEHRではEvaluationクラスの参照モデルで構成されるHealth risk assessmentアーキタイプです。openEHRで新規に臨床コンテンツを追加するということは、アーキタイプを新規に追加することに過ぎません(参照モデルは変更されません)。 一方、FHIRでは、新しいリソースを追加するか、既存のリソースについてのプロファイリングが必要となります。つまり、リソースを追加するために新たにソフトウェア開発が必要となることを意味します。
openEHRがよくカバーしていると私が信じている分野の1つは、汎用のクエリー言語であるAQLを使用するセマンティクスに対するクエリーです。私の知る限りでは、FHIRにはAQLに相当するものがありません。この汎用クエリーは唯一アーキタイプには依存しますが、それ以外の技術や物理的ストレージ構成には依存しないため強力です。
プラットフォームに不可欠な要素としてカバーする範囲は開発者の直接的な興味によって特定のあるいは別のエコシステムにがカバーする範囲へと変化しがちですが、それは何を使うのか、そしてどのような問題をどのように解決しようとしているのかということにつきます。
過剰評価と現実¶
もし、注意すべき点について一つだけ警告するとしたら、おそらく、「過剰評価」の問題については簡単に言及しておく価値があります。FHIRはこれまで非常に話題になってきました。その多くはIT業界の製品によくあるような過剰評価といってもいいでしょう。 これはFHIRプロジェクト固有の問題ではなくて、一般的な人間にある銀の弾丸の心理学 (ある一つの解決法ですべての問題が解決するという不合理な思い込み)と、ONCのような組織がHL7 v3への絶望とそれに変わるものとしての期待によるものが合わさってのものでしょう。過剰評価の大部分は、eHealth技術についてその複雑さや制約について十分な知識がないのにもかかわらずに過剰に楽天的である人々によって作られたものです。
私がおすすめするのは、要件が何であるかを注意深く考え、解決しようとしている課題についてのパラダイムについて理解を深めることだけです。たとえば、セマンティクスに関する方法論を求めるのであれば、それを実現しているプラットフォームや、すぐに利用できる商用のソリューションあるいは別の解決策のどれを利用したいかについて検討することです。次に利用できるさまざまな技術についてそのカバーする範囲を知りましょう。その技術が何に対応するものであって、そして何に対応していないのかについて把握しましょう。合理的な人であれば、単一の技術ですべての問題を解決することができないことが理解できるでしょう。そして、これはHL7 FHIRとopenEHRの両方にとっていえることでもあります。
openEHRとFHIRを連携させることはできますか?¶
この質問に対する答えは重要でもあり、取るに足りないものでもあります。もし、求められる要件が大手ベンダーによるレガシーシステムのためのアプリケーションや特定のBTB通信のためにデータを作成することであれば、FHIRは魅力的です。なぜなら、FHIRはまさにそのような問題を解決するために設計されたものであり、必要とされるすべての要件を満たすでしょう。
ただし、要件が長期にわたるオープンなヘルスケアインフラストラクチャプラットフォームを構築することであれば、調達しようとしている組織にとっては、データや主要なコンポーネント間のインターフェース、そしてそれらを購入する選択肢やタイミングを管理することも求められます。したがって、FHIRがカバーする範囲より多くのものが必要となるでしょう。このような視点で考えると、EHRは買えばすむという製品ではなくて、あなた自身が持つデータを管理するために構築していく機能をもつものです。
どのようにして、openEHRがオープンなプラットフォームインフラストラクチャの一部として設計されたのかという経緯についてはopenEHRのホワイトペーパーに書きました。通常、このような環境には、主要なレガシーシステムと電子カルテ(これはかなり国ごとの事情によります)が含まれるので、openEHRによるソリューションの主な仕事の一つは、必要なデータソースから高品質なモデルベースのセマンティックデータに変換するデータブリッジとしてメッセージを取り込むことです。
次の課題は、アプリケーションを構築できるように、プラットフォーム上のAPIを実装する方法です。歴史的にみて、openEHRのAPIについての考え方はIHEやMOGのサービスに近いものがあります。例えば、IHE PIX、PDQ、ATNAとOMG EISとのRLUです。最近、openEHRでは軽量のRESTインターフェース仕様レベルとEhrScapeのようなツールレベルで開発がすすめられています。このAPI仕様は、openEHR環境にネイティブAPIとメッセージングインターフェースを提供するものです。
EHRを調達しようとする機関が、openEHR環境のネイティブインターフェースに加えて、その上にFHIRを実装したい場合には、いくつか労力を伴います。そのためには2つのやり方があります。一つのやり方は、簡単なものです。基本的にはHL7 v2やCDAをチャネルを通じてシステムから取り出すように実装することです。いうなれば、要件となるFHIRリソースとAPIのためにそれぞれのカスタムインターフェースを実装して、openEHRのシステムからデータをAQLで取り出すことができるバックエンドのシステムを実装することです。新しいAPIを作っていくためにより多くの作業が必要となり、多くのユーザーにとって維持可能なものではありますが、かかるコストは青天井で増えていきます。
より強力でスケーラブルな方法は、FHIRの一般的な通信プラットフォームに新規に「リソースパーティション」を付け加えることです。たとえば、openEHRや、ISO 13606、CDISCまたは他のオープンコンテンツモデル空間にある情報モデルの定義に対応するものです。この方法の詳細については数ヶ月前に「みんなのためのFHIR開発」という記事に書きました。(この記事についてはHL7内でかなり強い抵抗があったといわせてください)。この方法の本質的な強みは、FHIRのやりかたで、そしてFHIRのアプリケーションを開発する方法そのままで、openEHR(またはISO13606やCDISC,BRIDGなど)のプログラムを書くことができることです。しかし、コンテンツインターフェースは、FHIR独自のリソースよりもむしろ、両方の長所が生かせるように関連するデータソースのモデルから機械的に導出したものとなるでしょう。
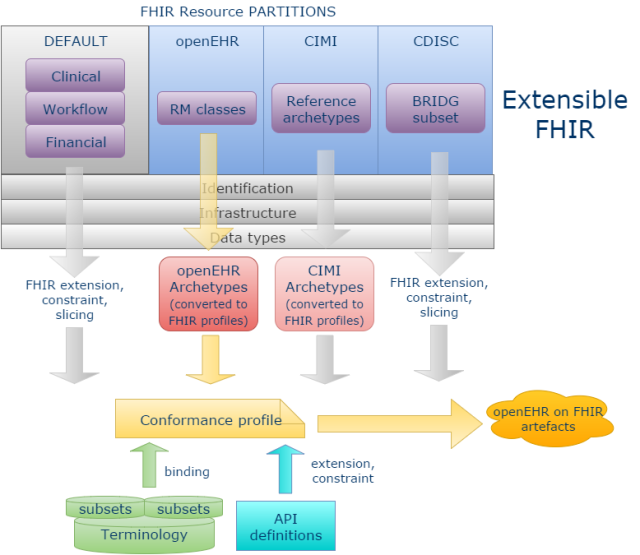
私は個人的に、この方法がFHIRとopenEHRのそれぞれの世界がともにすすんでいく最善の希望を表していると信じていますが、HL7がこのアイデアの価値を信頼してくれるかどうかについてはわかりません。
この記事がopenEHRととFHIRへの理解の助けとなり、特にそれらを一緒に使うような場合に有益な情報となることを望みます。
最終章(1月30日に追記)¶
私はこのことについての議論は以下のような考えで締めくくるのが妥当ではないかと思い至りました。つまり、eHealthなどの固有の複雑なセマンティクスを抱える分野で実際に働いている私達にとって、主要な課題はこのセマンティクスについてのモデルの共有ライブラリを開発していくことだと私は信じています。ここでも、「モデル」という単語が広い定義を意味しています。「モデル」とはその分野でのセマンティクスのすべての表現形式でありますが、ある流行にのった実装技術や製品とは明確に区別されて表現されます。
この考えには同意しない人もいるので、実現は不可能だという人もいるでしょう。しかし、合意にはいくつかの段階があります。「モデル」は特定の現象に対する理論を形式化したものであるということを考えてみましょう。(この記事に書きました 。)理論はわずか数人の人々が考え始めたものが、議論され、開発が行われて、検証をへて、作り直したりしながら、生き残ることもあれば滅んでしまうこともありますが、多くの人の心の中に広がっていきます。モデルは、合意された理論の単なる表現であり、合意の段階はどの程度その合意が共有されているかによって反映されます。
ヘルスケアでのコンピュータ利用の進むべき方向性としては、ヘルスケアのセマンティクスモデルとソリューションを実装する技術をどの時点においても完全に分離していくことです。
KOBAYASHI Shinji さんが約9年前に更新 · 9件の履歴